最大似然预期简述
最大似然预期是一种统计方法,它用来求一个样本集的有关几率密度函数的参数。这个方法最早是遗传学家以及统计学家罗纳德·费雪爵士在1912年到1922年间开始运用的。
“似然”是对likelihood 的一种较为贴近文言文的翻译,“似然”用现代的中文来看即“机会”。故而,若称之为“最大机会预期”则愈加通俗易懂。
最大似然法清晰地运用几率模型,其目标是寻求能够以较高几率造成观察报告的系统发生树。最大似然法是一类完全基于统计的系统发生树重建方法的代表。该方法在每组序列比对中考虑了每个核苷酸替换的几率。
比如,转换显现的几率大概是颠换的三倍。在一个三条序列的比对中,假使发现其中有一列为一个C,一个T和一个G,我们有理由觉得,C和T所处的序列之间的关系很有机会更靠近。受于被研究序列的共同祖先序列是未知的,几率的计算变得复杂;又受于或许在一个位点或多个位点发生多次替换,而且不是所有的位点均为相互独立,几率计算的复杂度更深一步加大。即使这样,依旧能用客观标准来计算每个位点的几率,计算表明序列关系的每棵或许的树的几率。然后,依据定义,几率总和最大的那棵树最有机会是反应真实情形的系统发生树。
最大似然预期的原理
给定一个几率分布
D,假定其几率密度函数(接连分布)或几率聚集函数(离散分布)为
fD,以及一个分布参数θ,我们可以从这个分布中抽出一个具有
n个值的采样
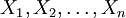
,通过利用
fD,我们就能计算出其几率:
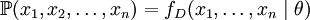
但是,我们或许不晓得θ的值,即使我们知道这些采样报告来自于分布
D。那么我们如何才可预期出θ呢?一个自然的想法是从这个分布中抽出一个具有
n个值的采样
X1,
X2,...,
Xn,然后用这些采样报告来预期θ.
一旦我们得到
,我们就能从中寻到一个有关θ的预期。最大似然预期会寻求有关 θ的最或许的值(即,在所有机会的θ取值中,寻求一个值使这个采样的“机会”最大化)。该种方法恰好同一部分其余的预期方法不同,如θ的非偏预期,非偏预期未必会输出一个最或许的值,而是会输出一个既不高估也不低估的θ值。
要在数学上达到最大似然预期法,我们首先要定义
机会:
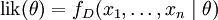
而且在θ的所有取值上,使这个注意这里的机会性是指
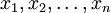
不变时,有关θ的一个函数。最大似然预期函数不一定是惟一的,甚至不一定存在。最大似然预期的例子离散分布,离散有限参数空间
考虑一个抛硬币的例子。如果这个硬币正面跟反面轻重不同。我们把这个硬币抛80次(即,我们获取一个采样
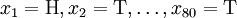
并把正面的次数记下来,正面记为H,反面记为T)。并把抛出一个正面的几率记为
p,抛出一个反面的几率记为1 −
p(所以,这里的
p即相当于上边的θ)。如果我们抛出了49个正面,31 个反面,即49次H,31次T。如果这个硬币是我们从一个装了三个硬币的盒子里头取出的。这三个硬币抛出正面的几率分别为
p = 1 / 3,
p = 1 / 2,
p = 2 / 3. 这些硬币没有标记,所以我们无法知道哪个是哪个。运用最大似然预期,通过这些试验报告(即采样报告),我们可以计算出哪个硬币的机会性最大。这个机会函数取下方三个值中的一个:
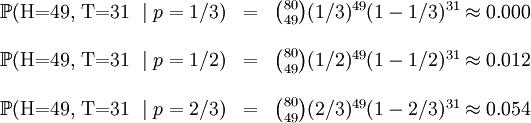
我们可以目睹当
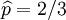
时,机会函数获得最大值。这就是
p的
最大似然预期.
离散分布,接连参数空间
当下如果例子1中的盒子中有无多个硬币,对于
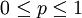
中的任何一个
p, 都有一个抛出正面几率为
p的硬币对应,我们来求其机会函数的最大值:
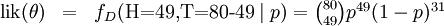
其中
.我们可以运用微分法来求最值。方程两边同期对
p取微分,并使其为零。
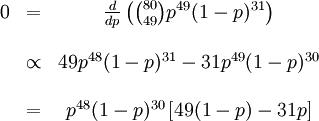
在不同比例参数值下一个二项式过程的机会性曲线
t = 3,
n = 10;其最大似然预期值发生在其众数(数学)并在曲线的最大值处。
其解为
p = 0,
p = 1,以及
p = 49 / 80. 使机会最大的解显然是
p = 49 / 80(由于
p = 0 和
p = 1 这两个解会让机会为零)。所以我们说
最大似然预期值为
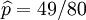
.
这个结果很容易一般化。只需要用一个字母
t代替49用以表达伯努利试验中的被观察报告(即样本)的'成功'次数,用其他字母
n代表伯努利试验的次数即可。运用完全同样的方法即可以得到
最大似然预期值:
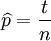
对于任何成功次数为
t,试验总数为
n的伯努利试验。
接连分布,接连参数空间
最常见的接连几率分布是正态分布,其几率密度函数如下:
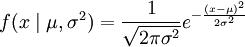
其
n个正态随机变量的采样的对应密度函数(如果其独立并服从同一分布)为:
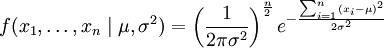
或:
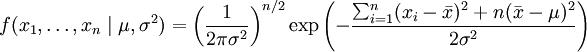
,
这个分布有两个参数:μ,σ2. 有人或许会担忧两个参数与上边的讨论的例子不同,上边的例子都导致在一个参数上对机会执行最大化。事实上,在两个参数上的求最大值的方法也差不多:只需要分别把机会
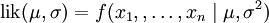
在两个参数上最大化即可。诚然这比一个参数麻烦一部分,但是一点也不复杂。运用上边例子同样的符号,我们有θ = (μ,σ2).
最大化一个似然函数同最大化它的自然对数是等价的。由于自然对数log是一个接连且在似然函数的值域内严格递增的函数。性质泛函不变性(Functional invariance)
假使
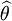
是 θ的一个最大似然预期,那么α =
g(θ)的最大似然预期是
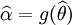
. 函数
g 无需是一个——映射。
渐近线举动
最大似然预期函数在采样样本总数趋于无穷的时机高达最小方差(其证明可见于Cramer-Rao lower bound)。当最大似然预期非偏时,等价的,在极限的情形下我们可以称其有最小的均方差。对于独立的观察来看,最大似然预期函数经常趋于正态分布。
偏差
最大似然预期的非偏预期偏差是非常重要的。考虑如此一个例子,标有
1到
n的
n张票放在一个盒子中。从盒子中随机抽取票。假使
n是未知的话,那么
n的最大似然预期值就是抽出的票上标有的
n,即使其期望值的只有(
n + 1) / 2. 为了预期出最高的
n值,我们能确定的只能是
n值不差于抽出来的票上的值。
">编辑]最大似然预期的一般求解步骤
基于对似然函数L(θ)形式(一般为连乘式且各因式>0)的考虑,求θ的最大似然预期的一般步骤如下:
(1)写出似然函数
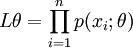
(总的X为离散型时)
或
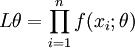
(总的X为接连型时)
(2)对似然函数两边取对数有
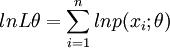
或
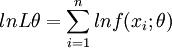
(3)对lnL\theta求导数并令之为0:
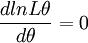
此方程为对数似然方程。解对数似然方程所得,即为未知参数 的最大似然预期值。
例1
设总的X~N(μ,σ2),μ,σ2为未知参数,
X1,
X2...,
Xn是来自总的X的样本,
X1,
X2...,
Xn是对应的样本值,求μ与σ2的最大似然预期值。
解 X的几率密度为
f(x;μ,σ2)=
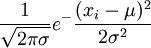
(
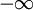 ),可得似然函数如下:L(μ,σ2)=
),可得似然函数如下:L(μ,σ2)=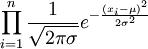 取对数,得lnL(μ,σ2)=
取对数,得lnL(μ,σ2)=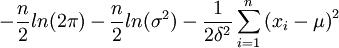 令
令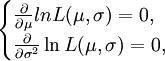 可得
可得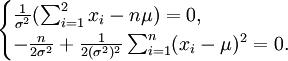 解得
解得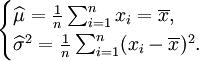 故μ和δ2的最大似然预期量分别为
故μ和δ2的最大似然预期量分别为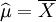 ,
,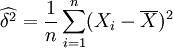 参考文献 ↑ 王翠香编著.几率统计.北京大学出版社,2010.02
参考文献 ↑ 王翠香编著.几率统计.北京大学出版社,2010.02
